들어가기
이 논문은 GAN 모델의 Latent vector를 임의로 조정하여 사람이 생성모델의 출력 결과를 제어할 수 있도록 인사이트를 제공해준다. 기저의 변동 요인(underlying variation factors)를 비지도 방식으로 해석하기 위해 GAN에 의해 학습된 내부의 representation을 파악한다. 특히, 생성 매커니즘에 대해 깊게 연구하여 직접 pretrained weights를 분해함으로써 latent semantic discovery를 위한 closed-form factorization 알고리즘을 발표한다.
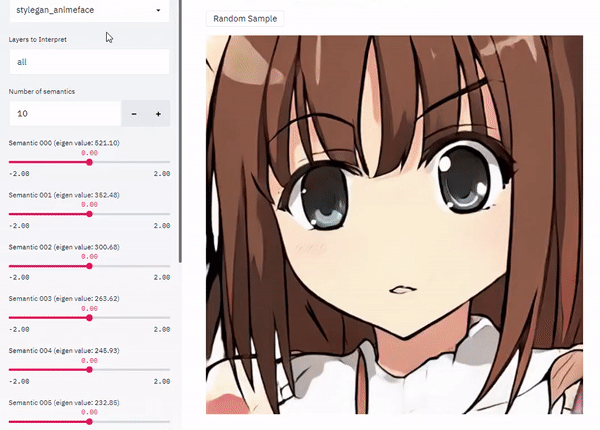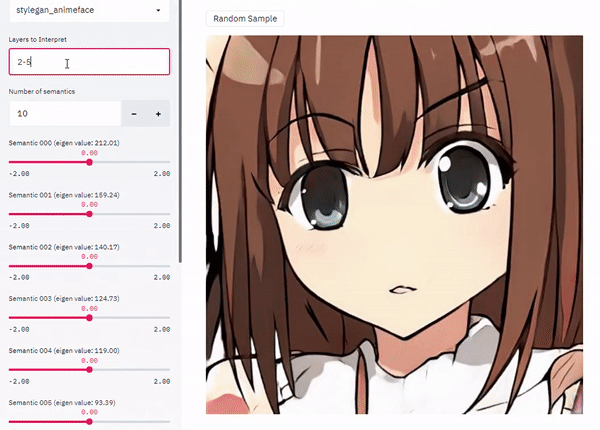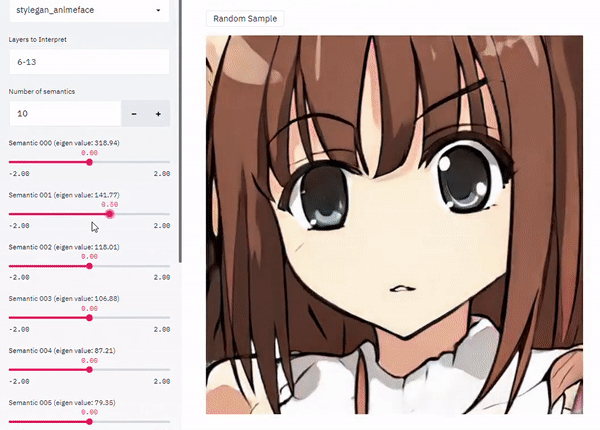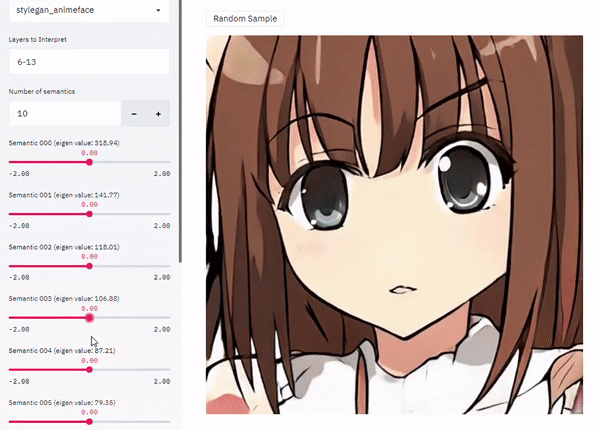
Introduction
GAN(Generative Adversarial Networks)는 이미지 합성 분야에서 큰 성공을 이뤄왔다. 최근 연구 결과, GAN 모델이 이미지 합성에 대해 학습할 때 Latent space에 자연스럽게 해석가능한 여러 속성(Multiple interpretable attributes)들이 표현되는 것이 발견되었다. 예를 들어, 사람 얼굴 합성 태스크에서 사람의 성별을 바꾼다던지, 장면 합성에서 광원이나 명암 등을 조절한다던지.
이러한 semantic attributes를 적절하게 식별함으로써 우리는 GAN이 학습한 Knowledge를 영상을 포함한 다양한 분야의 편집 애플리케이션에 재활용할 수 있게 된다.
GAN의 latent space를 이해하는 핵심은 인간이 이해할 수 있는 컨셉에 상응하는 유의미한 방향을 latent space 안에서 찾는 것이다. Latent space의 특정 code를 이미 식별된 방향으로 옮기거나 조정함으로써 출력 이미지의 semantic characteristic을 임의로 바꿀 수 있다.
하지만, latent space의 고차원적 특성과 이미지가 생성될 수 있는 수많은 경우의 수 때문에 Latent space에서 유의미한 방향을 찾는것은 정말 어렵다.
본 연구에서는 별도의 학습이나 샘플링없이 독립적으로 GAN이 학습한 latent semantic directions를 발견하기 위한 새로운 알고리즘을 제시한다. 이름하여, SeFa; the short for Semantic Factorization. SeFa는 GAN의 생성 매커니즘으로의 깊은 통찰을 통해 내부적인 representation과 출력 결과물(image variation) 사이의 연관성을 설명한다.
GAN은 latent code를 출력 결과로 단계적(step-by-step) 투영(project)한다. 각 단계(step)에서 하나의 step이 다른 하나의 step으로 투영된다. 그러므로 우리는 latent space에서 처음 발생하는 projection step에 대해서 조사할 것이다. 또한 이미 학습된 Generator를 활용함으로써 latent space로부터 다양한 semantics를 식별할 수 있는 closed-form이라는 메서드를 제안한다. 특히 이러한 variation factors는 SeFa에 의해 비지도 방식으로 찾게 되며, 다른 SOTA 지도 방식 메서드와 비교해봤을 때 더 정확하고 넓은 범위를 다룬다.
3D 모델이나 포즈 레이블에 대한 지식 없이 이미지에 존재하는 객체를 회전시키는 등의 실험을 Fig. 1처럼 해볼 수 있으며, 다양한 실험을 통해 우리의 제안이 다른 데이터셋으로 학습된 여러 GAN 파생 모델(PGGAN, StyleGAN, StyleGAN2, BigGAN 등)에 효율적이고 응용 가능하다는 것이 확인되었다.

Related Works
GAN
학습이 끝난 GAN 모델의 Generator는 latent space에서 랜덤하게 샘플링된 latent code를 input 데이터로 뽑아 높은 품질(fidelity)의 output 결과물을 생성한다. GAN 모델은 일반적으로 affine transformation을 사용하여, latent code가 첫번째 convolusion layer로 주입되는 deep convolutional neural networks로 구축된다. 최근에 이러한 아이디어는 Adaptive Instance Normalization(AdaIN) 연산을 통해 latent code를 layer-wise 방식의 code로 맵핑하여 각 convolution layer로 주입되는 StyleGAN, StyleGAN2의 Generator로 발전되었다.
Latent Semantic Interpretation
생성 모델은 관측된 데이터로부터 variation factors(변동 요인)을 학습하는데 탁월한 잠재력을 갖고 있다. Chen과 Higgins는 GAN이 이해할 수 있는 인수분해된 representation을 명시적으로 학습할수 있도록 학습 프로세스에 regularizers를 추가하였다. 최근의 연구에서는 별다른 constraints나 regularizers 없는 native GAN 모델이 자동적으로 중간 feature space나 initial latent space의 다양한 semantics를 인코딩할 수 있음을 발견하였다. 하지만 이러한 메서드는 대게 Supervised한 특성을 갖고 수행되며, 분류기를 학습하기 위해 이미지를 샘플링하거나 레이블을 만들어야 한다. PCA나 Joint learning을 활용한 Unsupervised semantic discovery와 관련한 연구들도 진행되었으나 이러한 연구들도 여전히 모델의 학습과 데이터 샘플링을 요구한다. 이들과는 다르게 우리 연구에서는 GAN의 생성 매커니즘에 대해서 분석하여, 어떠한 학습이나 샘플링이 필요없는 closed-form factorization 메서드를 제안한다.
Method
SeFa: closed-form method to discover latent interpretable directions in GANs를 소개한다. GAN의 생성 매커니즘에 대해서 깊게 파악하면 모델의 weights를 분리함으로써 latent space 안에서 semantically 유의미한 방향을 식별할 수 있다.
Preliminaries
Generation Mechanism of GANs
Generator G는 d-차원의 latent space ![]() 에서 더 높은 차원의 이미지 공간
에서 더 높은 차원의 이미지 공간 ![]()
![]() 으로의 맵핑을 학습한다. 이때, I는 Generator G의 출력
으로의 맵핑을 학습한다. 이때, I는 Generator G의 출력 ![]() 이다.
이다.
![]() 이고,
이고, ![]() 일 때, 전자와 후자는 각각 입력 latent code와 output 이미지를 나타낸다. SOTA GAN 모델들은 일반적으로 CNN을 G의 아키텍처로 도입하는데, 이때 G는 latent space에서부터 마지막 이미지 공간까지 step-by-step으로 projection한다. 각 step(단계)에서는 한 공간을 다른 공간으로 변환하는 과정을 학습하는데, 여기서는 latent space에서 직접 발생되는 첫 step에 대해서 집중 분석하겠다. 특히 이 과정은 affine transformation으로 공식화
일 때, 전자와 후자는 각각 입력 latent code와 output 이미지를 나타낸다. SOTA GAN 모델들은 일반적으로 CNN을 G의 아키텍처로 도입하는데, 이때 G는 latent space에서부터 마지막 이미지 공간까지 step-by-step으로 projection한다. 각 step(단계)에서는 한 공간을 다른 공간으로 변환하는 과정을 학습하는데, 여기서는 latent space에서 직접 발생되는 첫 step에 대해서 집중 분석하겠다. 특히 이 과정은 affine transformation으로 공식화 ![]() 할 수 있다.
할 수 있다.
이때 ![]() 는 m-차원의 projected code이며,
는 m-차원의 projected code이며, ![]()
![]() 와
와![]() 는 첫 변환 step에서의 weight와 bias를 나타낸다.
는 첫 변환 step에서의 weight와 bias를 나타낸다.
Manipulation Model in GAN Latent Space
GAN의 Latent space는 풍부한 semantic knowledge를 인코딩한다. 이러한 semantics는 벡터 연산을 통해 이미지 편집에 응용될 수 있다. 구체적으로는, latent space의 특정 차원의 direction을 사용하여 semantic 컨셉을 표현하는 연구들이 진행되었다. semantically 유의미한 방향이 식별되면 다음 수식을 통해 이미지 조작이 가능해진다.