편향? 분산? 머신러닝과 무슨 상관인가
지도학습(Supervised Learning)에 대해서 이야기를 할 때는
사람이 정해준 정답이 있고, 컴퓨터가 그 정답을 잘 맞추는 방향으로 훈련(training)을 시킵니다.
정답 하나를 맞추기 위해 컴퓨터는 여러 번의 예측값 내놓기를 시도하는데,
컴퓨터가 내놓은 예측값의 동태를 묘사하는 표현이 '편향' 과 '분산' 입니다.
예측값들과 정답이 대체로 멀리 떨어져 있으면 결과의 편향(bias)이 높다고 말하고,
예측값들이 자기들끼리 대체로 멀리 흩어져있으면 결과의 분산(variance)이 높다고 말합니다.
활쏘기로 비유를 들어 봅니다.
아래 그림을 보시면, 가운데 빨간 점이 사람이 정해준 '정답'이고
파랗게 여러 번 찍힌 점이 컴퓨터가 예측한 값들 입니다.
- 왼쪽 상단 과녁은
예측값들이 대체로 정답 근방에서 왔다갔다 합니다.->편향이 낮습니다.
예측값들끼리 서로 몰려 있습니다.->분산이 낮습니다.
- 오른쪽 상단 과녁은
예측값들이 대체로 정답 근방에서 왔다갔다 합니다.->편향이 낮습니다.
예측값들끼리 서로 흩어져 있습니다.->분산이 높습니다.
- 왼쪽 하단 과녁은
예측값들이 대체로 정답으로부터 멀어져 있습니다.->편향이 높습니다.
예측값들끼리 서로 몰려 있습니다.->분산이 낮습니다.
- 오른쪽 하단 과녁은
예측값들끼리 대체로 정답으로부터 멀어져 있습니다.->편향이 높습니다.
예측값들끼리 서로 흩어져 있습니다.->분산이 높습니다.

같은 말을 수식으로 표현해 봅니다.
수식은 핵심적인 개념을 전달하는 매우 유용한 수단입니다.
단지 너무 핵심만 전달하다 보니, 이해를 제대로 하거나 아예 못하거나 둘 중 하나가 되어버리는 경우가 많죠.
찬찬히 살펴보면
수식이란 우리가 그림을 그리고 놀 때처럼 뭔가를 '표현'하는 수단인 것이지,
형법 민법 처럼 그것을 지켜야만 하는 법 조항이 아니라는 것을 알 수 있습니다.
- x는 데이터를 의미합니다. 여기서는 파랑 점 하나 하나가 x가 될 수 있습니다.
- f(x)는 데이터가 향해야 하는 정답 을 의미합니다.
파란 점 x가 어떤 값을 갖든 관계없이, f(x)는 단일한 정답을 의미하겠죠. - f(x)에 ^ 표시가 있는 것은 f hat x 라고 읽습니다.
hat은 머리에 쓰는 모자 라는 뜻인데, 수학에서는 '특정 값' 을 지칭할때 사용합니다.
여기서는 특별히, 컴퓨터가 내놓은 예측값들을 표현하는 기호로 사용했습니다. - E[ ] 이것은 기대값(expectation)을 의미합니다. 쉬운 말로 평균 이죠.
f^(x)는 예측값'들' 이므로, 여러 예측값'들'이 자기들끼리 반장선거해서 선출된 대표님을 의미할때 사용합니다.

편향(bias) 을 수식으로 표현해봅니다.
빨강 점과 회색 점에 대한 이야기입니다.
편향이란, 예측값이 정답과 얼마나 다른가(차이가 있는가, 떨어져 있는가, 멀게 있는가 등등) 를 표현합니다.
E[f^*(x)] : 예측값 들의 평균 입니다. 위 그림에서 회색 점과 같은 의미입니다.
f(x): 정답값 입니다. 위 그림에서 빨간 점과 같은 의미입니다.
둘을 빼면 정답과 예측값이 서로 떨어진 거리를 알 수 있지요.
이 거리는, 정답과 예측값들이 서로 가까운지 먼 지를 알려주는 지표입니다.
그런데 제곱을 해 준 이유는,
어떤 예측값은 정답보다 클 것이고, 어떤 예측값은 정답보다 작을 것이기 때문에
두 값 사이의 거리는 양수가 나오기도, 음수가 나오기도 하기 때문입니다.
제곱을 해서 모두 양수를 만들어 주면, 값들을 '쌓는 것'이 가능해집니다. 그럼 얼마나 쌓였는지를 나중에 따로 잴 수가 있죠.
꼭 제곱을 사용해야만 하는 것은 아니고, 절대값을 씌워 주는 것도 좋은 방법입니다.
양수를 만들기 위한 목적이니까, 4제곱, 6제곱을 해 주어도 관계없지요.
그러나 같은 목적을 달성하는데 가장 손쉬운 계산방법은 제곱 을 하는 것이므로,
거리를 재는 수식에서는 제곱을 해 주는 것이 그냥 상식처럼 되었습니다.

분산(variance)을 수식으로 표현해봅니다.
파란 점들과 회색 점에 대한 이야기입니다.
'예측값'(위 그림에서 파란 점들)과, '예측값들의 평균(위 그림에서 회색 점)'의 차이
를 평균내어 제곱 해줍니다.
이렇게 하면, 예측값들이 자기들끼리 서로 얼마나 흩어져 있는가 를 표현할 수 있습니다.

두 식을 그저 더해서 전체적인 경향을 표현합니다.
다음은 '파랑 점 하나(예측값)' 를 x로 보고 표현한 식입니다.
화살을 한 번 쐈을 때(=예측을 한 번 했을 때) 오차(Error)를 나타낸 것이죠.
모든 파랑 점들을 가지고 Error를 표현하려면, 파랑 점 각각에 대해서 아래 계산을 반복해서 수행하면 되겠습니다.
![]()
아래 기호는 irreducible error, 그러니까 무슨 짓을 해도 줄일 수 없는 근본적인 오차를 의미합니다.
실제로 계산할 수 있는 값은 아니고, 의미적으로만 이해하면 되겠습니다.
![]()
편향과 분산은, 머신러닝 모델이 '복잡하게 생긴 정도'와 큰 관련이 있습니다.
아래 세 그림은, 세 가지 서로다른 머신러닝 모델로 같은 데이터를 설명하는 모습입니다.
회귀(Regression) 모델인데요.
정답들은 '점'으로 찍혀 있고
모델이 내놓을 예측값은 직선 혹은 구불구불한 곡선으로 표현되어 있습니다.
이 문제에서는 여러 점들의 경향을 표현하는 모델을 찾는 것이 목적입니다.
첫 번째 그림을 보시면, 데이터들이 모델과 멀어져 있으므로 편향(bias)이 높고,
모델이 내놓는 값들 끼리는 별로 떨어져 있지 않게 되므로(왜냐면 같은 직선위의 점들이니까) 분산(variance)은 낮습니다.
세 번째 그림을 보시면, 정답들이 모델과 아주 붙어 있으므로 편향이 낮고,
모델이 내놓는 값들 끼리는 매우 흩어져 있게 되므로(왜냐면 구불구불한 선 위의 점들이니까) 분산이 높습니다.
두 번째 그림 정도가 어지간히 적당하다 고 볼 수 있죠.

아래 세 그림은, 역시 세 가지 서로 다른 머신러닝 모델로 같은 데이터를 설명하는 모습입니다.
분류(classification) 모델인데요.
정답들은 빨강 동그라미 혹은 초록 십자가로 찍혀 있고
모델이 내놓을 예측값은 직선 혹은 구불구불한 곡선으로 표현되어 있습니다.
이 문제에서는 빨강 동그라미와 초록 십자가를 잘 구분하는 모델을 찾는 것이 목적입니다.
첫 번째 그림을 보시면, 데이터들이 모델과 멀어져 있으므로 편향(bias)이 높고,
모델이 내놓는 값들 끼리는 별로 떨어져 있지 않게 되므로(왜냐면 같은 직선위의 점들이니까) 분산(variance)은 낮습니다.
세 번째 그림을 보시면, 정답들이 모델과 아주 붙어 있으므로 편향이 낮고,
모델이 내놓는 값들 끼리는 매우 흩어져 있게 되므로(왜냐면 구불구불한 선 위의 점들이니까) 분산이 높습니다.
두 번째 그림 정도가 어지간히 적당하다 고 볼 수 있죠.

Underfitting, Overfitting
회귀 문제이든, 분류 문제이든
첫 번째 그림과 같은 상황을 Underfitting
세 번째 그림과 같은 상황을 Overfitting이라고 합니다.
모델이 너무 단순하게 생겼으면(=훈련이 너무 덜 되어 있으면) 정답을 잘 내놓지를 못하고
모델이 너무 복잡하게 생겼으면(=훈련이 너무 심하게 되어 있으면),
훈련용 데이터를 모조리 외워서 잘 맞추는 지경이기 때문에
새로 제시되는 데이터에 대해서 틀린 답을 내놓을 가능성이 높습니다.
훈련이 적당히 되면 좋겠지만, 뭐든지 '적당히 하기'가 가장 어렵죠.
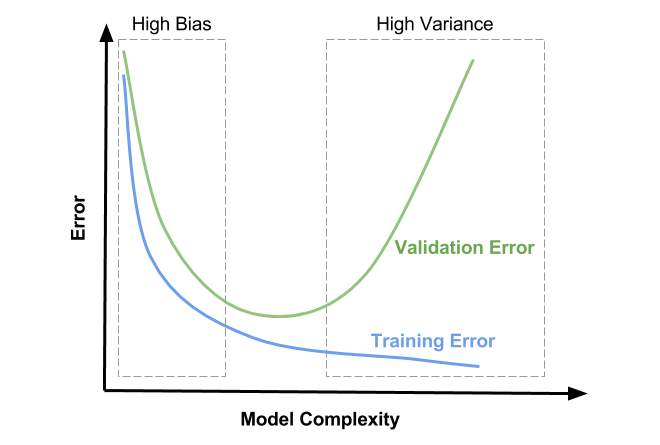
Model Complexity
편향(Bias)과 분산(Variance)은
한쪽이 증가하면 다른 한쪽이 감소하고,
한쪽이 감소하면 다른 한쪽이 증가하는 경향을 보입니다.
모델이 데이터를 반복 학습하는 횟수가 늘어날수록 모델이 복잡한 정도(Model Complexity)도 따라서 늘어나게 되는데,
이것은 훈련용 데이터를 그대로 외우는 방향이기 때문이죠.
따라서 Training Error는 갈수록 줄어들게 되지만
Validation Error는 어느 정도까지는 줄어들다가, 어느 지점 이후부터는 다시 상승하게 됩니다.
모델을 훈련시키는 도중에 Validation Error가 최소인 지점에서 훈련을 멈추는 것이 필요하죠.
다음 강의에서 자세히 다루겠지만,
Training Error는 training용 데이터로 모델을 훈련시킬 때 발생하는 오차이고,
데이터가 모델의 내부 구조를 변화시키면서 이 오차를 줄이는 것이 모델의 지향하는 바 입니다.
반면 Validation Error는 데이터로 모델을 평가할 때 발생하는 오차이며,
데이터가 모델의 내부 구조를 변화시키지 않고, 그저 validation용 데이터를 집어넣었을 때
모델이 어떤 결과를 내놓는지만을 관찰합니다.